
Orekit provides an automatic filtering feature for data loaded through a DataProvidersManager instance. All filters implement the DataFilter interface and can be registered to a DataProvidersManager instance. In the default configuration, three filters are registered:
GzipFilter which uncompresses files compressed with the gzip algorithmUnixCompressFilter which uncompresses files compressed with the Unix compress algorithmHatanakaCompressFilter which uncompresses RINEX files compressed with the Hatanaka methodUpon load time, all filters that can be applied to a set of data will be applied. If for example a file is both encrypted and compressed (in any order) and filters exist for uncompression and for deciphering, then both filters wiil be applied in the right order to the data retrieved by the DataProvider before being fed to the DataLoader.
The following class diagrams shows the main classes and interfaces involved in this feature.
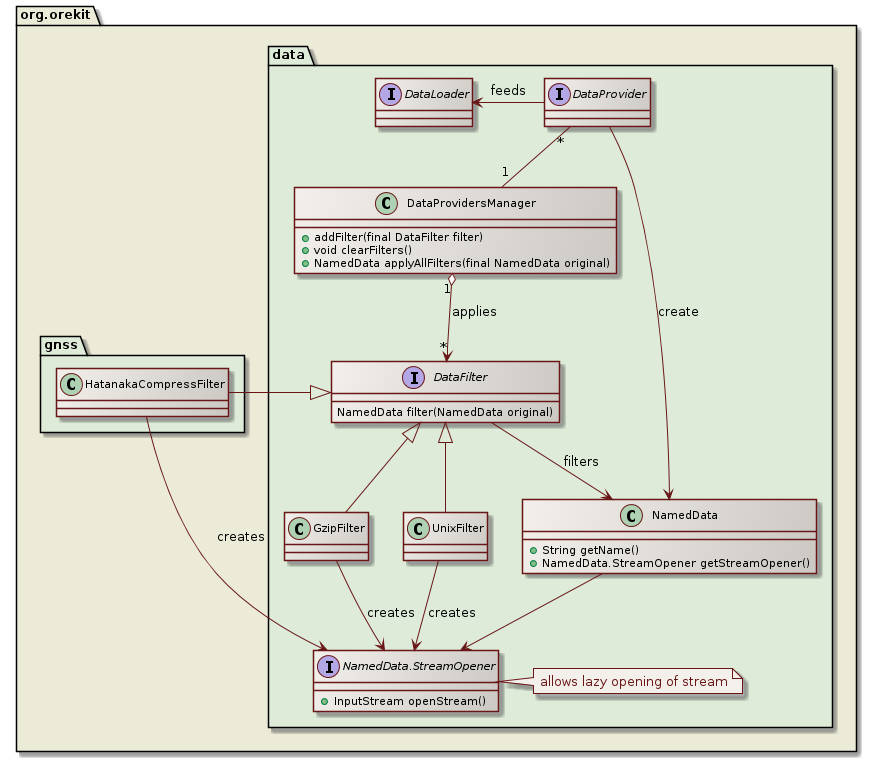
The filtering architecture is based on a stack of NamedData instances, with at the bottom an instance created by a DataProvider that will read bytes directly from storage, then some instances added by the DataProvidersManager.applyAllFilters method, each one reading bytes from the underlying stack element and providing filtered bytes to the next element upward. If at the end the name part of the NamedData matches the name that the DataLoader instance expects, then the byte stream of the top of the stack is opened. This is were the lazy opening occurs, and it generally ends up with all the intermediate bytes streams being opened as well. The opened stream is then passed to the DataLoader to be parsed. If on the other hand the name part of the NamedData does not match the name that the DataLoader instance expects, then the full stack is discarded and the next resource/file from the DataProvider is considered for filtering and loading.
One example will explain this method more clearly. Consider a DirectoryCrawler configured to look into a directories tree containing files tai-utc.dat and MSAFE/may2019f10_prd.txt.gz, one of the defaults filters: GzipFilter that uncompress files with the .gz extension (the defaults filters also include UnixCompressFilter and HatanakaCompressFilter, they are omitted for clarity), and consider MarshallSolarActivityFutureEstimation which implements DataLoader and can load files whose name follow a pattern mmmyyyyf10_prd.txt (among others).
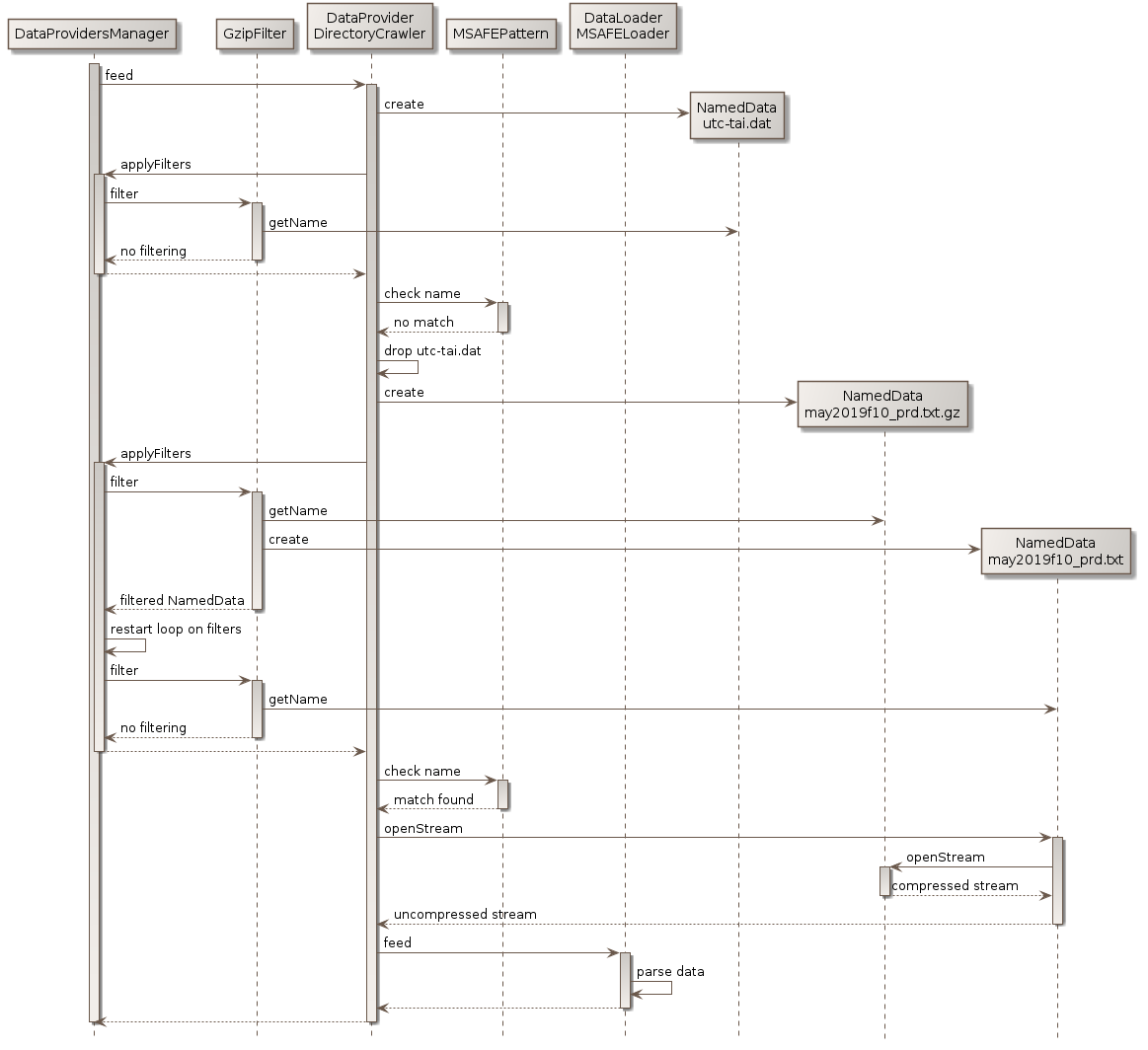
When the tai-utc.dat file is considered, a NamedData is created for it. Then the filters are checked (only one filter shown in the diagram), and all of them decline to act on the file, so they all return the same NamedData that was created for the raw file. At the end of the filters loop, the name (which is still tai-utc.dat) is checked against the expected pattern. As it does not match, the stack composed of only one NamedData is discarded. During all checks, the file as not been opened at all, only its name has been considered.
The DirectoryCrawler then considers the next directory, and in this directory the next file which is may2019f10_prd.txt.gz. A new NamedData is created for it and the filters are checked. As the extension is .gz, the GzipFilter filter considers it can act on the file and it create and returns a new NamedData, with name set to may2019f10_prd.txt and lazy stream opener set to insert an uncompressing algorithm between the raw file bytes stream and the uncompressed bytes stream it will provide. The loop is restarted, but no other filter applies so at the end the stack contains two NamedData, the bottom one reading from storage and providing gzip compressed data, and the top one reading the gzip compressed data, uncompressing it and providing uncompressed data. As the name of the top instance matches the expected pattern for MSAFE data, the MarshallSolarActivityFutureEstimation will be able to load it. At this stage, the DirectoryCrawler calls the method to open the bytes stream at the top level of the stack. This method then asks the underlying NamedData to open its stream (which it the raw file data), feeds the gzip uncompression algorithm with this data and provides the output uncompressed data as a newly opened bytes stream. The data loader then parses the data, without knowing that is is uncompressed on the fly.