
The Orekit library relies on some external data for physical models. Typical data are the Earth Orientation Parameters and the leap seconds history, both being provided by the IERS or the planetary ephemerides provided by JPL. Such data is stored in text or binary files with specific formats that Orekit knows how to read. These files can be embedded with an application built on top of Orekit or externally provided.
Orekit must be configured appropriately to find and use such data.
For user convenience, data that is only a few tens of kilobytes and can be assumed to never change like precession-nutation models are already embedded in the core library. Small and simple data sets are defined by setting constants in the code itself. This is the case for the 32.184 seconds offset between Terrestrial Time and International Atomic Time scales for example. Large or complex data sets are embedded by copying the corresponding resource files inside the compiled jar, under the assets directory as is. This is the case for the IAU-2000 precession-nutation model tables for example. There is nothing to configure for these data sets as they are embedded within the library, so users may ignore them completely.
Other types of data sets correspond to huge or changing data sets. These cannot realistically be embedded within a specific version of the library in the long run. A typical example for such data set is Earth Orientation Parameters which are mandatory for accurate frames conversions. Another example is planetary ephemerides. IERS regularly publishes new Earth Orientation Parameter files covering new time ranges whereas planetary ephemerides represent megabytes-sized files. These data sets must be provided by users and Orekit must be configured to find and read them at run time.
In order to simplify data updates for users and to avoid transformations errors, Orekit uses each supported data set in the native format in which it is publicly available. So if a user wants to take into account the Earth Orientation Parameters for a given year, for example, he will simply download the corresponding file for IERS server at http://www.iers.org/IERS/EN/DataProducts/EarthOrientationData/eop.html and drop it in the data storage system Orekit is configured to use, without any change to the data file itself.
If a data set format changes or a new data set should be supported, a modification of the reading classes inside Orekit would be needed. This design choice has been selected because format changes remain rare (except IERS EOP data perhaps ...).
Data sets must be stored at locations where the Orekit library will find them. This may be simply a directories tree on a disk, but may be almost anything else as this simple solution would not fit all uses of the library.
The following use cases show different possible data storage strategies. All of them can be handled by Orekit plugin mechanism. Most of the plugins are already available in the library itself.
In this case, data may be stored in the main operational database, relying on the existing administration procedures (updates, backup, redundancy ...).
For everyday local use of a tool, data will mainly be stored in the user environment. A traditional architecture will involve two main data stores, one on a network shared disk for large general data sets handled at department level and another one as simple files on the local user disk where he can put his own data sets for specific purposes. The local data files may be set up in order to override system-level values for special cases.
If a program using Orekit is integrated in an existing environment with its own established data management system, the library must be configured to use this system to retrieve the data instead of using its own internal system. This enables smoother integration. It also simplifies system administration of the complete suite. It may even allow sharing some of its data with other tools.
An application used on a small device with network access (say a mobile phone), may be simpler to set up and use if it does not store the data at all on the device itself but retrieves it on the fly from the web when needed.
A service installed on an application server may be simpler to configure if, rather than using explicit files locations on the server, one stores the data in the application classpath where it will be managed by the application server together with the application code itself.
A demonstration program can be distributed using Java WebStart so that any user can download it and try it almost instantly from a public web site. If the application is not signed, it will run in a sandbox environment for security reasons (the application is not trusted). The sandbox prevents access to the user disk. Data must be embedded within the application jar file, in the internal classpath.
The following diagram shows data handling in Orekit.
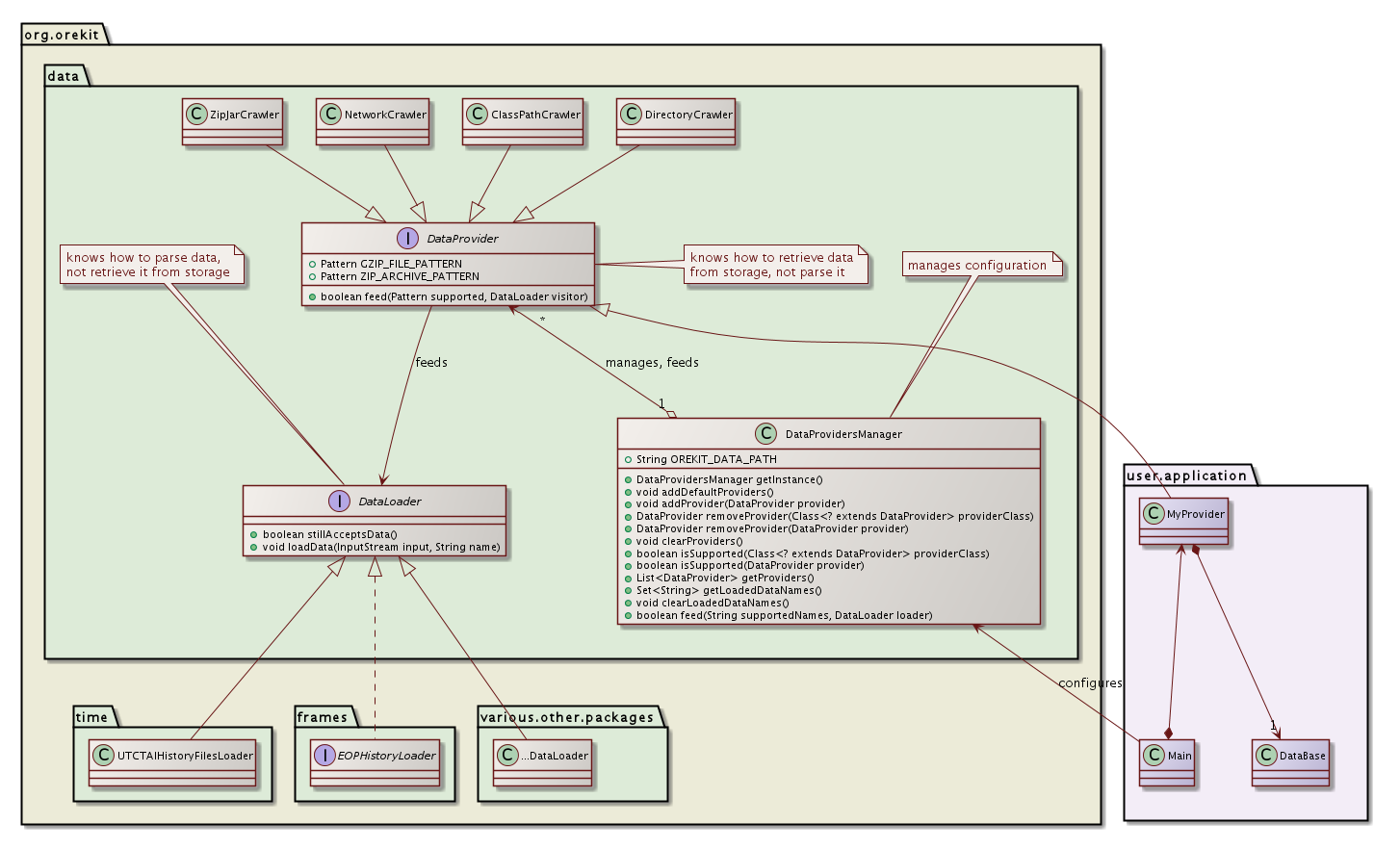
When some data is read in Orekit (say JPL DE405 or DE406 ephemerides which are needed by the CelestialBodyFactory class), an implementation of the DataLoader interface is used. By default, it will be JPLEphemeridesLoader (this can be customized). This implementation knows the type of files it can handle based on their names (unxp1950.405, unxp2000.405 ...). It also knows the file format and what to do with the data. The data loader does not know where the data is and does not open the file itself.
The task to locate and fetch the data is performed by classes implementing the DataProvider class. Each implementation is dedicated to one storage type (disk, classpath, direct download on network, access to a database, delegation to a user defined library ...). The providers crawl their storage medium and for each stored file ask the data loader if it supports the file according to its name. If the data loader supports it, then the provider will fetch the data from the storage medium and feed the loader with it.
Which data loader to use is straightforward. The CelestialBodyFactory class for example can only handle JPL ephemerides so only one data loader can be used. It is hardcoded in the CelestialBodyFactory class as the default loader. Which data provider to use is customizable. The singleton class DataProvidersManager manages all the providers that should be used for data loading. The manager will typically be configured at application initialization time, depending on the use case and perhaps configuration data (environment variables, Java properties, users preferences ...). If the manager is not configured, a default configuration is set up.
The default configuration is based on a single Java property named orekit.data.path. This property should be set to a list of directories trees or zip/jar archives containing the data files Orekit can use. The property is set up according to operating system conventions, i.e. the list elements are colon-separated on Linux and Unix type operating systems, and semicolon-separated on Windows type operating systems. One data provider will be set up for each list element, either a DirectoryCrawler if the element refers to a directory or ZipJarCrawler if the elements refers to a zip or jar archive (i.e. if its name ends in .zip or .jar).
This default configuration only uses static local storage (or network shared disk). It doesn't connect to anything, neither for downloading a regular file nor to extract a bunch of bytes from a database. It also does not look in the classpath for data. If such needs arise, then a custom configuration must be set up.
Any number of directories trees or zip/jar archives may be used, each list element simply adds one data provider to the list. The list elements are used in the order in which they are defined, one at a time. If one data providers succeeds in feeding the data loader, then the loop over the providers is stopped and the remaining providers (or list elements) are ignored. When a data provider is used, all the files it holds will be checked and loaded if supported. This means that if a data set is spread over several files, like the JPL ephemerides or the Earth Orientation Parameters for example, then these files must be handled by the same provider. The provider will take care to load them all but since it succeeds no other provider will be used. This design choice allows setting up configurations where users provide their own subsets of data (for example Earth Orientation Parameters only) and prevent the system wide configuration to be used for this subset while still using the rest of the data (for example JPL ephemerides) from the system tree. Users do so by putting their own directories in front of the big system-level directories in the property.
Directories trees or zip/jar archives may be used interchangeably. They both basically represent container for files or other directories trees or zip/jar archives. Orekit opens zip/jar archives on the fly and crawls into them as if they were regular directories, without writing anything to disk.
Data files may also be compressed using gzip to save some disk space. Compressed files are also uncompressed directly in memory. Compressing text-based files like Bulletin B or EOPC04 saves a lot of disk space, but compressing the JPL binary files saves very little space. Using compressed files inside a zip archive is also irrelevant as zip/jar files are themselves compressed and stacking compression algorithms only slows down reading speed without saving any disk space.
Since nothing is written to disk (there are no temporary files), user provided data sets may be stored on non-writable media like disk partitions with restricted access or CD/DVD media.
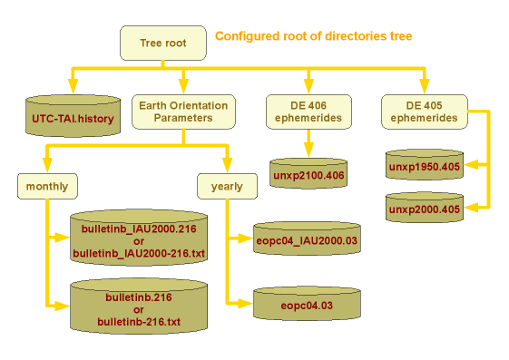
There is no mandatory layout within the data directories trees or zip/jar archives. Orekit navigates through them and their sub-directories when looking for data files. Files are identified by pattern matching rules on their names. Files that don't match the rules are silently ignored. This allows the user to share the data directories trees with other tools which need a specific layout or additional files. The layout presented in the figure above is a simple example.
As with any other Java property, orekit.data.path can be initialized at application launch time by the user (for example using the -D flag of the virtual machine) or from within the application by calling the System.setProperty method. In the latter case, rather than the literal string constants orekit.data.path, the OREKIT_DATA_PATH static field from the DataProvidersManager class can be used. If the property is set up by the application, it must be done before any Orekit feature is called, since some data are initialized very early (mainly frame and time related data like leap seconds for UTC).
If the default configuration doesn't suit users needs, a custom configuration must be set up. This happens for example if data must be embedded within the application and loaded from the classpath. This also happens if the data must be retrieved from a dynamic or virtual storage medium like a database, a web site or a local data handling library.
The configuration corresponds to the list of data providers stored in the DataProvidersManager singleton. In order to set up a custom configuration, the singleton must be purged and specific data providers must be added in an appropriate order.
The data providers predefined by the Orekit library are the following ones:
Users can also add their own implementations of the DataProvider interface and register them to the DataProvidersManager singleton. Typical examples of user defined implementations are providers fetching data from a relational database or providers fetching data using an external library. This corresponds to the plugin feature announced above.
For convenience, a zip file containing some default data is available for download on orekit forge: https://www.orekit.org/forge/projects/orekit/files. Setting the orekit.data.path property to the location of this file on a local computer is enough to use Orekit efficiently, but the preferred setup is to expand the zip file in the user home folder so that new IERS files can be added easily when they become avialble. In this case, data is loaded by puttin the following code in the main application:
final File home = new File(System.getProperty("user.home"));
final File orekitDir = new File(home, "orekit-data");
final DataProvider provider = new DirectoryCrawler(orekitDir);
DataProvidersManager.getInstance().addProvider(provider);This zip file contains JPL DE 406 ephemerides from 1962 to 2029, IERS Earth orientation parameters from 1973 to end 2012 with predicted date to mid-2013 (both IAU-1980 and IAU-2000), UTC-TAI history from 1972 to end of 2013, Marshall Solar Activity Future Estimation from 1999 to 2013 and the Eigen 06S gravity field.
The data types supported by Orekit are described in the following table, where the # character represents any digit, (m/p) represents either the m character or the p character and * represents any character sequence. The [.gz] part at the end of all naming patterns means that an optional .gz suffix can be appended, in which case the data are considered to be compressed with gzip.
Earth Orientation Parameters are provided by observatories in many different formats (Bulletin A, several different formats of Bulletin B, EOP 08 C04, finals file combining both Bulletin a and Bulletin B information ...). They are also provided for different precession-nutation models (IAU-1980 and IAU-2006/2000A). Orekit supports all of these formats except Bulletin A and supports both precession-nutation models. Two different naming patterns for Bulletin B are supported by default. Both the old Bulletin B format used up to 2009 and the new format used since 2010 are supported. The supported formats for finals2000A files for IAU-2006/2000A and the finals files for IAU-1980 are both the XML format and the columns format.
| default naming pattern | format | data type | source |
| UTC-TAI.history[.gz] | IERS history | leap seconds introduction history | http://hpiers.obspm.fr/eoppc/bul/bulc/UTC-TAI.history |
| bulletinb_IAU2000-###.txt[.gz] | IERS Bulletin B | monthly Earth Orientation Parameters model IAU 2006/2000A | ftp://ftp.iers.org/products/eop/bulletinb/iau2000/ |
| bulletinb_IAU1980-###.txt[.gz] | IERS Bulletin B | monthly Earth Orientation Parameters model IAU 1980 | ftp://ftp.iers.org/products/eop/bulletinb/iau1980/ |
| eopc04_08_IAU2000.##[.gz] | IERS EOP 08 C04 | yearly Earth Orientation Parameters model IAU 2006/2000A | ftp://ftp.iers.org/products/eop/long-term/c04_08/iau2000/ |
| eopc04_08.##[.gz] | IERS EOP 08 C04 | yearly Earth Orientation Parameters model IAU 1980 | ftp://ftp.iers.org/products/eop/long-term/c04_08/iau1980/ |
| finals2000A.*.[.gz] | IERS standard EOP | Earth Orientation Parameters model IAU 2006/2000A | ftp://ftp.iers.org/products/eop/rapid/standard/finals2000A.data ftp://ftp.iers.org/products/eop/rapid/standard/finals2000A.all |
| finals.*.[.gz] | IERS standard EOP | Earth Orientation Parameters model IAU 1980 | ftp://ftp.iers.org/products/eop/rapid/standard/finals.data ftp://ftp.iers.org/products/eop/rapid/standard/finals.all |
| finals2000A.*.xml[.gz] | IERS standard EOP | Earth Orientation Parameters model IAU 2006/2000A | ftp://ftp.iers.org/products/eop/rapid/standard/xml/finals2000A.data.xml ftp://ftp.iers.org/products/eop/rapid/standard/xml/finals2000A.all.xml |
| finals.*.xml[.gz] | IERS standard EOP | Earth Orientation Parameters model IAU 1980 | ftp://ftp.iers.org/products/eop/rapid/standard/xml/finals.data.xml ftp://ftp.iers.org/products/eop/rapid/standard/xml/finals.all.xml |
| (l/u)nx(m/p)####.4##[.gz] (l/u)nxm####p####.4##[.gz] | DE 4xx binary | JPL DE 4xx planets ephemerides | ftp://ssd.jpl.nasa.gov/pub/eph/planets/Linux/ |
| inpop*_m####_p####*.dat[.gz] | DE 4xx binary big/little endian | IMCCE inpop planets ephemerides | ftp://ftp.imcce.fr/pub/ephem/planets/ |
| eigen_*_coef | SHM format | Eigen gravity field (old format) | http://op.gfz-potsdam.de/grace/results/main_RESULTS.html#gravity |
| *.gfc or g###_eigen_*_coef | ICGEM format | gravity fields from International Centre for Global Earth Models (ICGEM) | http://icgem.gfz-potsdam.de/ICGEM/modelstab.html |
| egm##_to#* | EGM format | EGM gravity field | ftp://cddis.gsfc.nasa.gov/pub/egm96/general_info |
| Jan####F10.txt to Dec####F10.txt | MSAFE format | Marshall Solar Activity Future Estimation | http://sail.msfc.nasa.gov/archive_index.htm |